안녕하세요~ 이전에 셀레니움 카테고리에서 웹 페이지 크롤링 하는 방법에 대해 설명해드렸는데요
이번에는 request 이용해서 웹 페이지 크롤링 하는 방법에 대해서 조금 상세하게 다뤄볼까 해요
(잡설이 불필요하신 분들은 포스팅 하단의 코드만 가져다 이용하세요 ^^)
크롤링 대상 사이트는 '나라장터 - > 용역 -> 사전규격공개' 페이지 입니다.
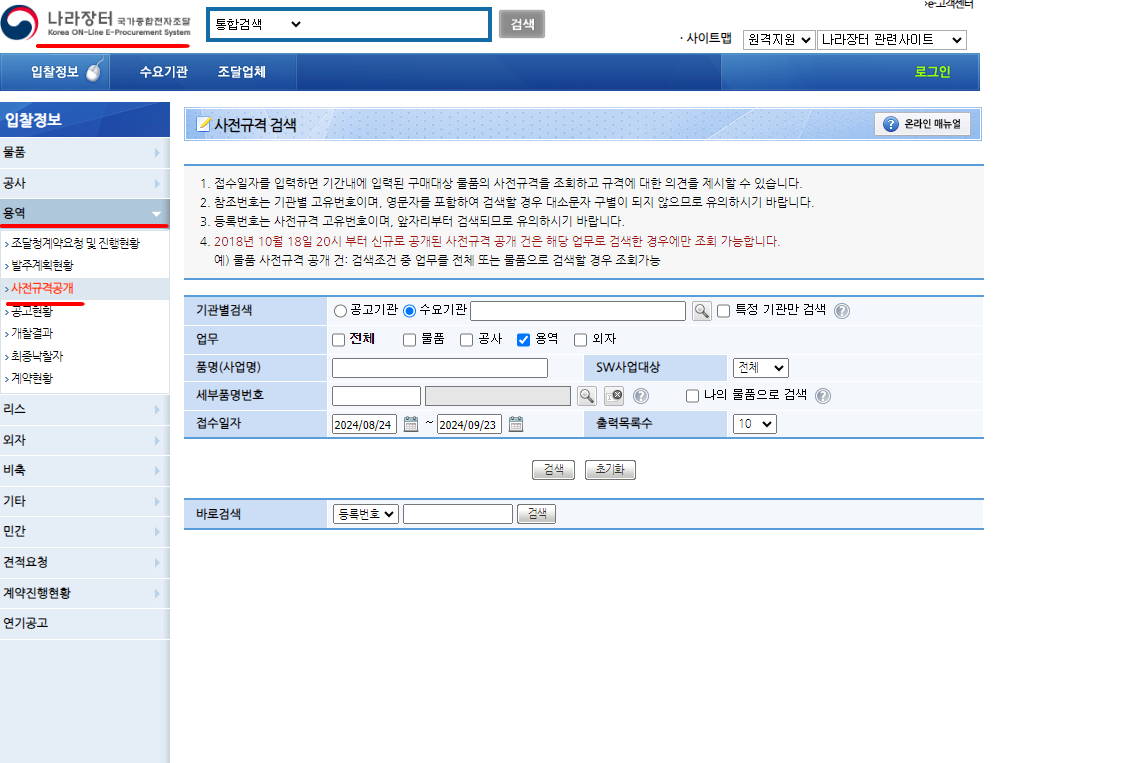
크롤링을 할 때에는 웹 페이지가 어떻게 데이터들을 불러오는지에 대해 상상하며 코드를 작성하면 좋습니다.
위 이미지 페이지로 이동해서, 사업명을 검색해볼게요

이때, 웹 페이지에 마우스 우클릭 -> 맨 밑에 있는 검사(1) -> 네트워크 보기(2) 를 열어두어야 합니다.



그 다음 검색 버튼을 누르면 아래 이미지와 같이 나와요!
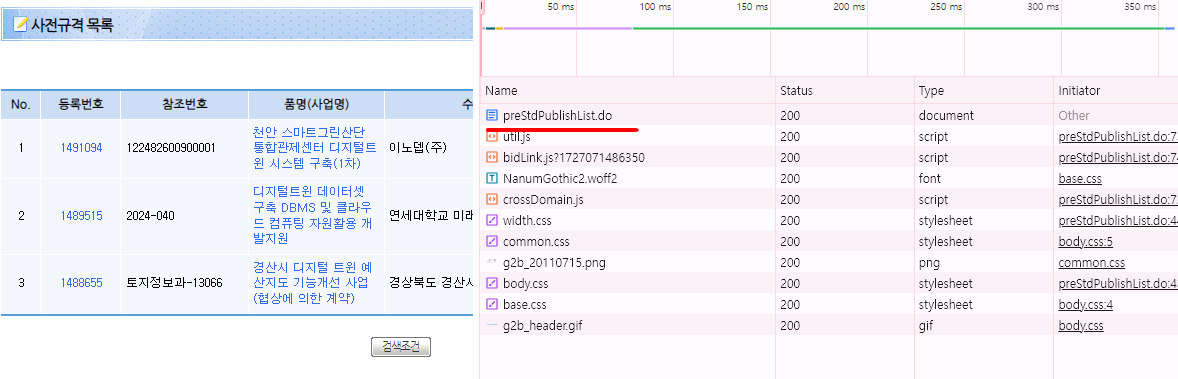
여기에서 첫번째 애를 클릭 후 Preview 를 눌러보면 아래 이미지 처럼 우리가 필요한 정보가 담겨있는걸 확인할 수 있습니다!!!

자, 그럼 이걸 본격적으로 크롤링 해볼까요??
payload 부분을 살펴보면 Form Data가 들어있는게 보입니다.
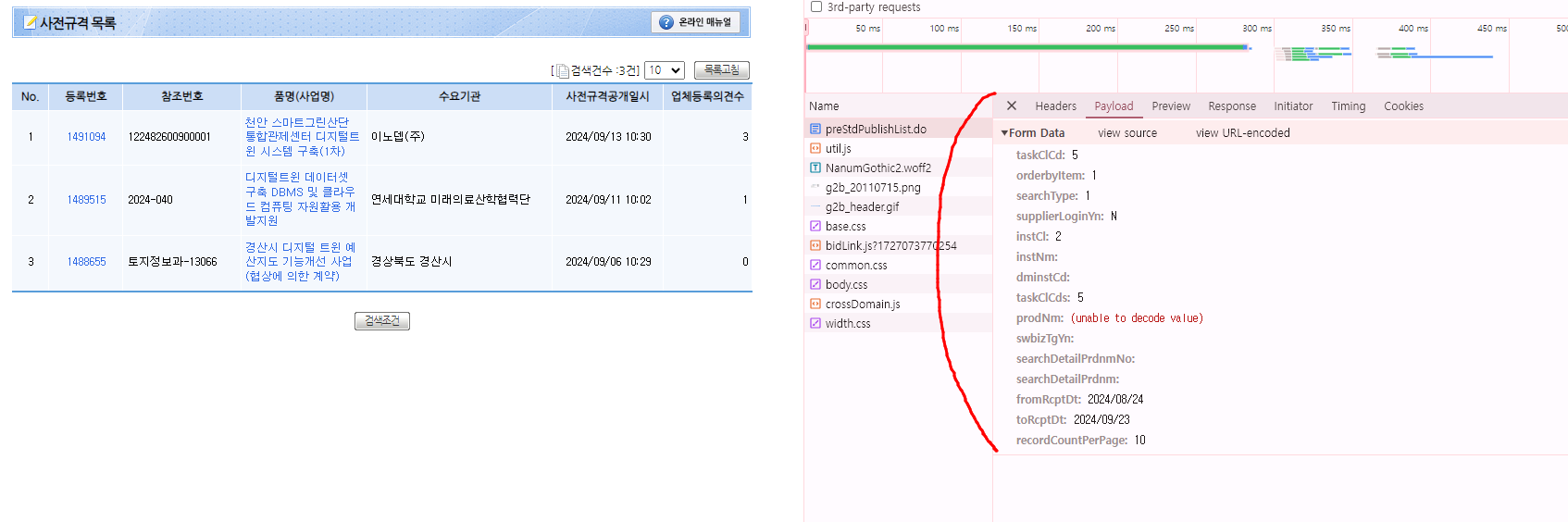
위 이미지에서 prodNM 값이 검색어인데 한글이라 (unable to decode value)로 표시된 것으로 의심됩니다
(decode, incode 관련해서는 오늘 포스팅에서 다루기가 어려우니 패스하도록 하겠습니다.)
fromRcptDt:2024/08/24 와 toRcptDt:2024/09/23 는 각각 시작날짜와 종료날짜로 보이네요,
recordCountPerPage:10 는 한 페이지에 표시되는 목록 수 인거같죠??
아래 이미지에서의 payload 값을 이용해서 request post 하는 코드를 작성해보겠습니다.
우선 payload 값을 복사하기 편하게, view source 를 클릭해줍니다.


위 정보들을 바탕으로 크롤링 하는 코드를 작성하면~~
아래와 같이 작성할 수 있구요 ^^
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 23 15:10:11 2024
@author: Rogio
"""
import requests
import urllib.parse
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://www.g2b.go.kr:8081/ep/preparation/prestd/preStdPublishList.do'
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
}
# 문자열
검색어 = '트윈'
시작날짜 = "2024/08/24"
종료날짜 = "2024/09/23"
# EUC-KR로 인코딩 후 URL 인코딩
encoded_검색어 = urllib.parse.quote(검색어.encode('euc-kr'))
# 인코딩 디코딩 관련 문제 때문에 payload 작성 방법이 이전 포스팅과 다릅니다.
payload = (
f"taskClCd=5&"
f"orderbyItem=1&"
f"searchType=1&"
f"supplierLoginYn=N&"
f"instCl=2&"
f"instNm=&"
f"dminstCd=&"
f"taskClCds=5&"
f"prodNm={encoded_검색어}&"
f"swbizTgYn=&"
f"searchDetailPrdnmNo=&"
f"searchDetailPrdnm=&"
f"fromRcptDt={시작날짜}&"
f"toRcptDt={종료날짜}&"
f"recordCountPerPage=10"
)
response = requests.post(url, data=payload, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
print(soup)
사전규격목록 = soup.find('table')
사전규격목록_table = pd.read_html(str(사전규격목록))[0]
코드 실행해보면



이렇게 일치한 결과를 받아올 수 있답니다 !!
검색된 결과를 엑셀로 저장하는 방법 같은건 이전 포스팅을 참고해주시면 감사하겠습니다~
(https://rogios-story.tistory.com/entry/httpsrogios-storytistorycomentryselenium-g2b-Crawling-4-4)
위 링크로 접속하셔서 "엑셀로 저장" 을 검색해주세요~

p.s 오늘은 어떤분께서 제 포스팅을 보고 따라하시다 막혔던 부분을 긁어드렸습니다.
급하게 만드느라 자세한 설명이 부족한 감이 있는데 ,이 포스팅을 참고하시면서 궁금한 내용이 있으시면 댓글로 남겨주세요~